Last Updated or created 2022-08-04
I use several tools to find files on my server.
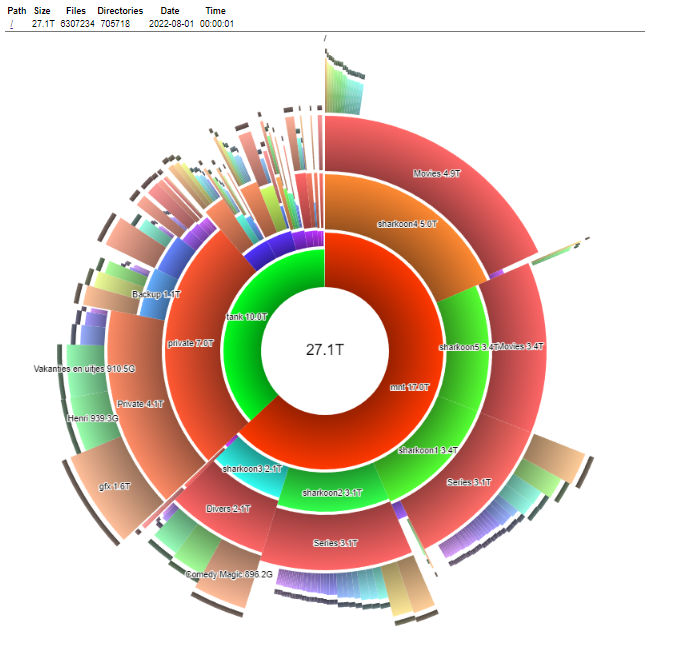
(Graph is a great tool called DUC) https://duc.zevv.nl/
Besides a search engine, i have a file finder.
Due to the massive amount of data, i like to find things by other means than knowing the directory structure.
I can find files by filename, but also by contents.
I’ll talk about find by contents first.
I’ve got loads of documents in Pdf, HTML, txt, doc, sheets , wordperfect etcetera.
Those documents i can find using a tool named Namazu.
This is quite a old tool, but i’m using it for a long time and it still works great.
I didn’t find a better replacement yet.
(But i’ve been looking into : elasticsearch, Solr, Lucene)
http://www.namazu.org/ is easy to install, but if you want the tool to scrape different kinds of documents you have to add some additional software.
My multipurpose printer can scan pages in pdf.
Those are only embedded jpg’s in a pdf container.
I will talk about how i handle these later.
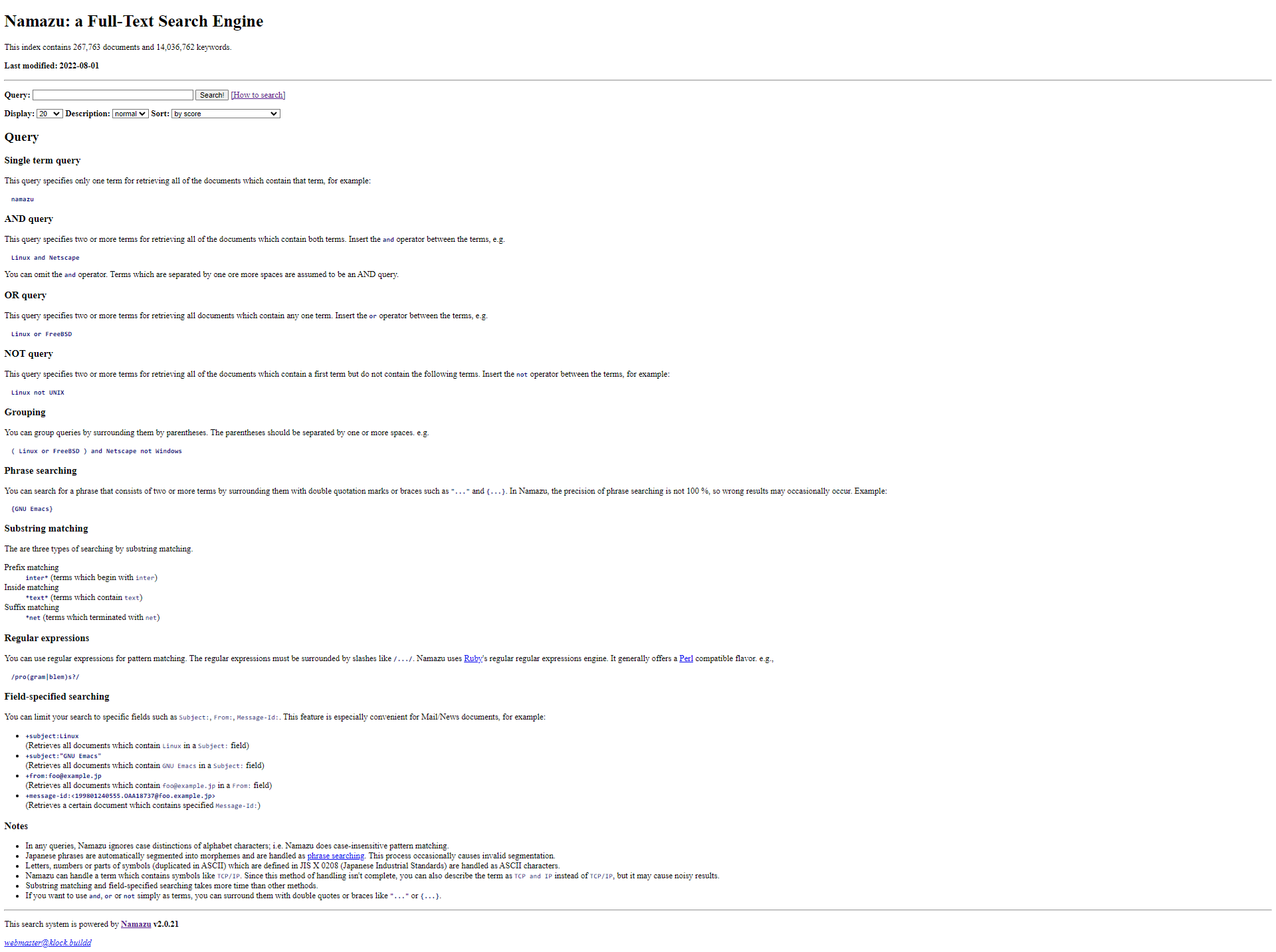
This index contains 267,763 documents and 14,036,762 keywords.

Some things to consider when implementing namazu:
- tweak the file types to scrape, it makes no sense to scrape binaries
- tweak the directories to scrape (example below)
- 0 1 * * 1 fash /usr/bin/mknmz -f /etc/namazu/mknmzrc –output-dir=/namazu/ /mnt/private/paperwork/ /mnt/private/information/ /mnt/private/Art\ en\ hobby\ Projects/ /mnt/private/Music\ Projects/ /mnt/private/bagpipe-music-writer/ –exclude=XXX –exclude=/mnt/binaries > /tmp/namazu.log 2>&1
- you can set a parameter in the config for search only, this disables downloading the found link in the results!
Before Namazu i used HtDig.
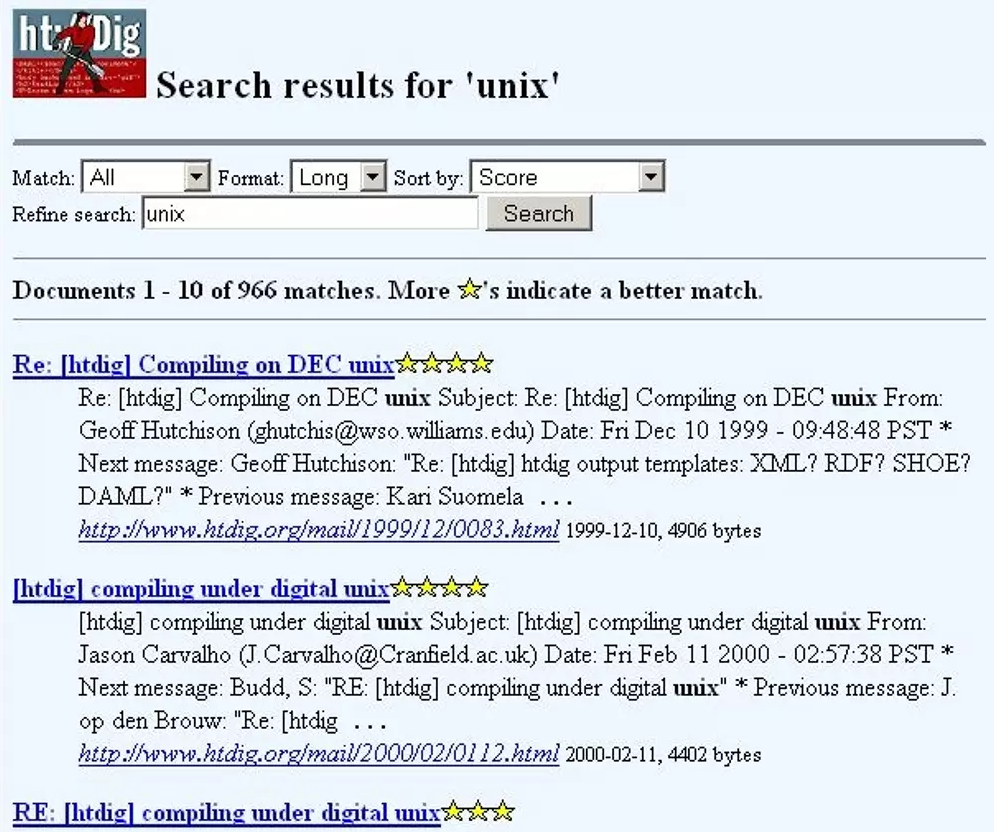
HtDIg also can scrape remote websites, Namazu can’t.
Preparing PDF for indexing:
I’ve written some scripts to make PDFs containing scanned text scrape-able.
( https://gitlab.com/fash/inotify-scanner-parser )
What it does:
- My scanner puts a scanned pdf on my fileserver in a certain directory
- Inotify detects a written file
- it will copy the file, run OCR on it (tesseract) and writes a txt file (scapeable)
- After that the text will be embedded (overlay) on the PDF, so now it becomes searchable/scrapeable
- When certain keywords are found, it will sort documents in subdirs

(note .. the overlay is exact on the found words)
Finding files by name:
For finding files a made a little webpage like this:
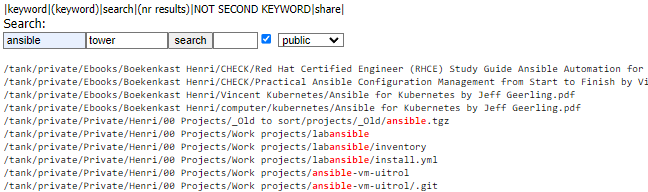
It is a simple webpage grabbing through a list of files.
It takes the first keyword and does a grep, it takes a second keyword to match also.
I can select different file databases to search. (This case is private)
Between search and private i can give the number of entries to print.
So i can do
Search “ansible” NOT “tower” 50 entries from the public fileset
Crontab:
20 5 * * * /usr/bin/find /mnt/shark* > /var/www/html/findfiles/sharkoon 10 4 * * * /usr/bin/find /tank/populair > /var/www/html/findfiles/populair 20 4 * * * /usr/bin/find /tank/celtic > /var/www/html/findfiles/celtic etc
And a php script (dirty fast hack, never came around it to make it a final version)
<html><head><title></title></body>
<font face="Tahoma"><small>|keyword|(keyword)|search|(nr results)|NOT SECOND KEYWORD|share|</small><BR>
Search: <form method="post" action="/findfiles/?"><input type="Text" name="words" size=10 value=""><input type="Text" name="words2" size=10 value=""><input type="Submit" name="submit" value="search"><input type="Text" name="nrlines" size=3 value=""><input type="checkbox" name="not" unchecked>
<SELECT NAME=findfile>
<OPTION VALUE=private>private
<OPTION VALUE=celtic>celtic
<OPTION VALUE=populair>populair
<OPTION VALUE=dump>public
<OPTION VALUE=sharkoon>sharkoon
</SELECT>
</form>
<P><PRE>
<?php
$words2=$_POST['words2'];
$words=$_POST['words'];
$filefile=$_POST['filefile'];
$findfile=$_POST['findfile'];
$nrlines=$_POST['nrlines'];
$not=$_POST['not'];
if ($words2=="xsearch") { $findfile="other"; $words2=""; }
if ($nrlines) { } else { $nrlines=100; }
if ($words && $words2=="") {
$words = preg_replace("(\r\n|\n|\r)", "", $words);
$words = preg_replace("/[^0-9a-z]/i",'', $words);
$command = "/bin/cat $findfile |/bin/grep -i $words |head -$nrlines";
$blah=shell_exec($command);
$blah=str_replace($words, "<b><font color=red>$words</font></b>",$blah);
print $blah;
}
if (($words) and ($words2)) {
$words = preg_replace("(\r\n|\n|\r)", "", $words);
$words = preg_replace("/[^0-9a-z.]/i",'', $words);
$words2 = preg_replace("(\r\n|\n|\r)", "", $words2);
$words2 = preg_replace("/[^0-9a-z.]/i",'', $words2);
if ($not=="on") {
$command = "/bin/cat $findfile |/bin/grep -i $words | /bin/grep -iv $words2 |head -$nrlines";
} else {
$command = "/bin/cat $findfile |/bin/grep -i $words | /bin/grep -i $words2 |head -$nrlines";
}
$blah=shell_exec($command);
$blah=str_replace($words, "<b><font color=red>$words</font></b>",$blah);
$blah=str_replace($words2, "<b><font color=red>$words2</font></b>",$blah);
print $blah;
}
?>
</PRE>
</body></html>