3D printed a little light case for a wemos and a piece of WS2812 led strip I had lying around.

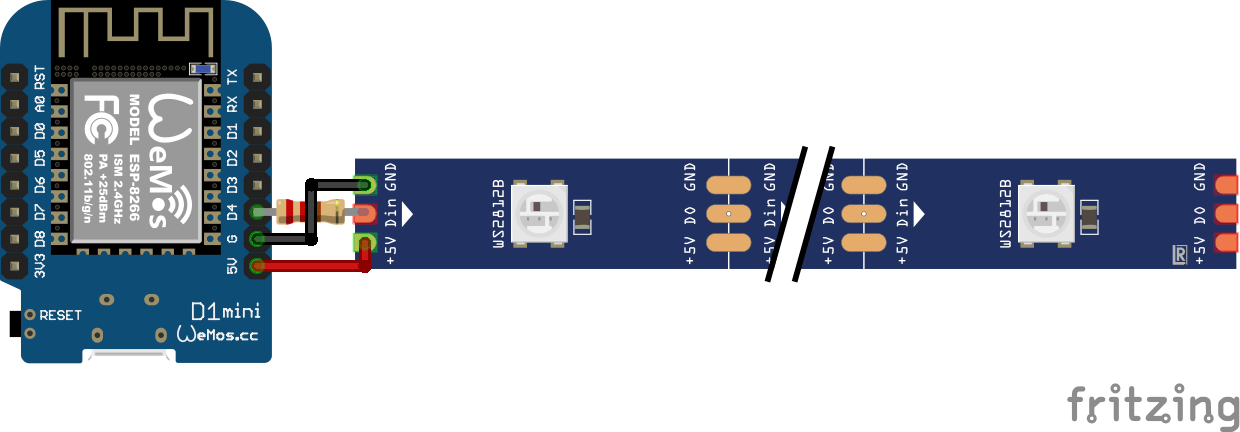
Schematic:
NOTE: The resistor is 100-500 ohm (I forgot, just try)
You can only use this trick for a few leds (I used 4), else you better can use the sacrifice a led to make a level shifter trick.
(Wemos logic is 3.3V and the led strip is 5V)
I flashed ESPHome on the wemos using the flasher in Home Assistant.
Code:
esphome:
name: matternotification
friendly_name: matternotification
esp8266:
board: d1_mini
# Enable logging
logger:
# Enable Home Assistant API
api:
encryption:
key: "ogFxZUXerNxxxxxxxxxxxxxxxxxWaWyJVxCM="
ota:
- platform: esphome
password: "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
wifi:
ssid: !secret wifi_ssid
password: !secret wifi_password
# Enable fallback hotspot (captive portal) in case wifi connection fails
ap:
ssid: "Matternotification"
password: "rxxxxxxxxxxxxxxx"
captive_portal:
light:
- platform: neopixelbus
type: GRB
variant: WS2812
pin: D4
num_leds: 4
name: "NeoPixelMattermost"
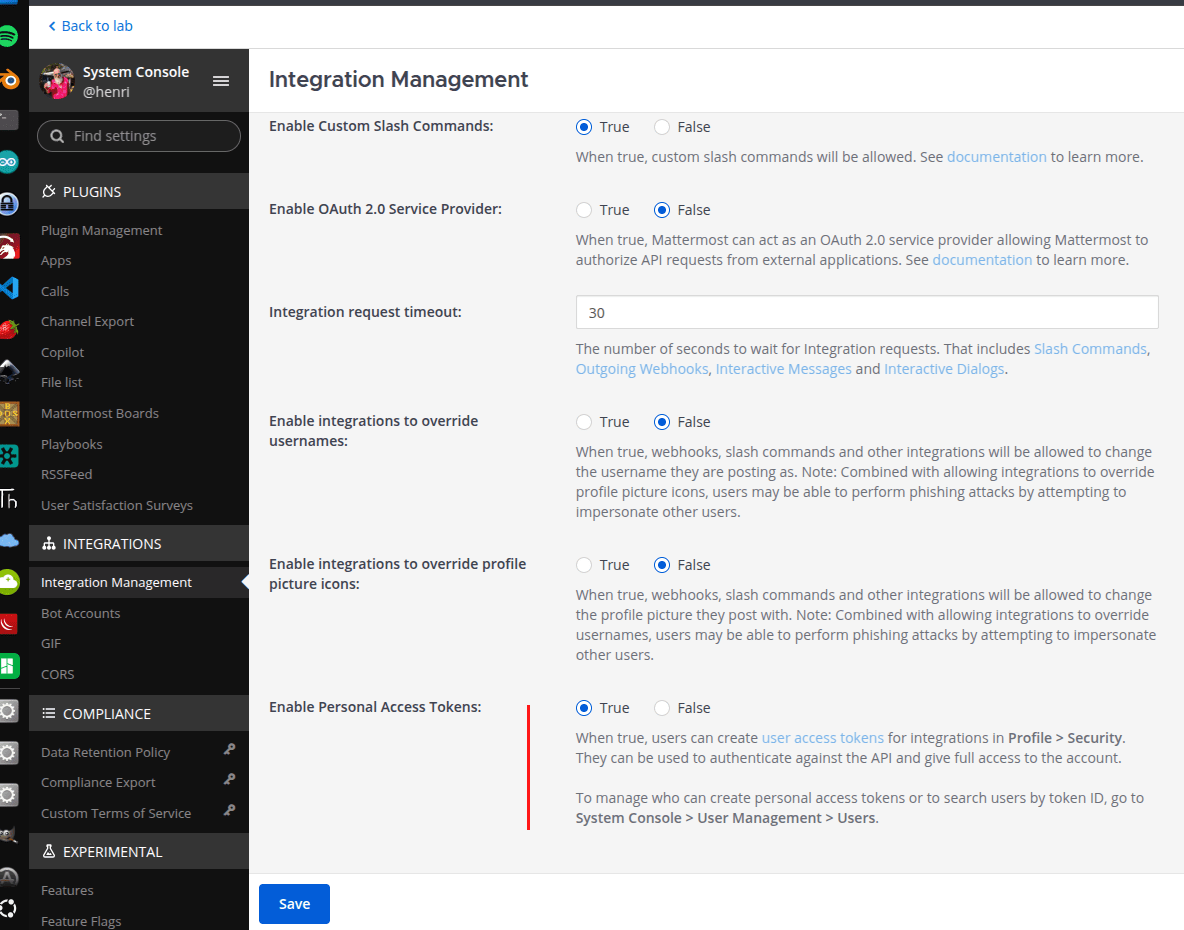
To get the status of messages and controlling the HA entity, I made a bash script.
First curl command to get a token from Mattermost using the API.
Second curl command to get messages states from Mattermost.
Bottom two curl command turn a light entity on or off in your Home Assistant server using a API
#!/bin/bash
#set -x
# change : mattermost username and password (and server)
# change : mattermost userid and teamid
# change : home assistant long time token (and HA server)
# change : light entity
#
while true; do
# Get token using login
#token=$(curl -s -i -X POST -H 'Content-Type: application/json' -d '{"login_id":"username","password":"password"}' https://mattermostinstance.com/api/v4/users/login | grep ^Token | awk '{ print $2 }' | tr -d '\r' )
#using a MM auth token (see below)
token=xxxxxxxxxxxxxxxxxxxx
# Get messages
# Gives you something like
# {"team_id":"j3fd7gksxxxxxxxxxxxxxjr","channel_id":"rroxxxxxxxxxxxxxxtueer","msg_count":0,"mention_count":0,"mention_count_root":0,"urgent_mention_count":0,"msg_count_root":0}
# We need to count ":0"
messages=$(curl -s -i -H "Authorization: Bearer ${token}" https://mattermostinstance.com/api/v4/users/ou5nz5--USER-UUID--rbuw4xy/channels/rropejn--TEAM-ID--tueer/unread | grep channel
| grep -o ":0" | wc -l)
# If 5 times ":0" then no messages
if [ $messages == 5 ] ; then
# Turn off
curl -s -X POST -H "Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cC--HOME-ASSISTANT-LONG-TIME-TOKEN-CBusTgTUueWpPNdH5WAWOE" \
-H "Content-Type: application/json" \
-d '{"entity_id": "light.matternotification_neopixelmattermost_2"}' \
http://192.168.1.2:8123/api/services/light/turn_off > /dev/null
else
# Turn on
curl -s -X POST -H "Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cC--HOME-ASSISTANT-LONG-TIME-TOKEn--CBusTgTUueWpPNdH5WAWOE" \
-H "Content-Type: application/json" \
-d '{"entity_id": "light.matternotification_neopixelmattermost_2"}' \
https://192.168.1.2:8123/api/services/light/turn_on > /dev/null
fi
sleep 5
done
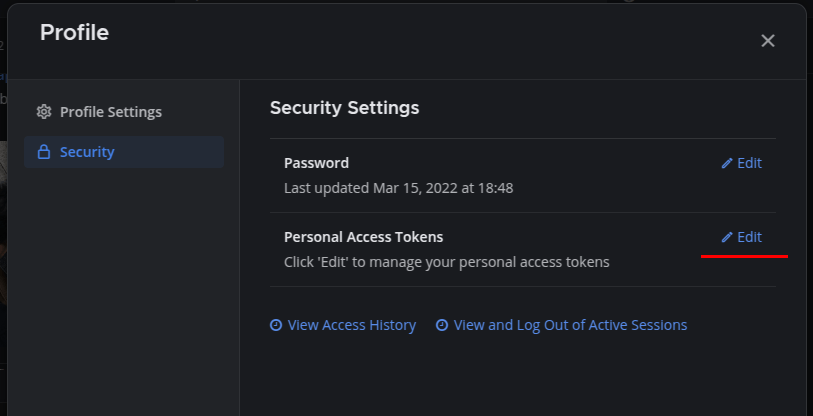
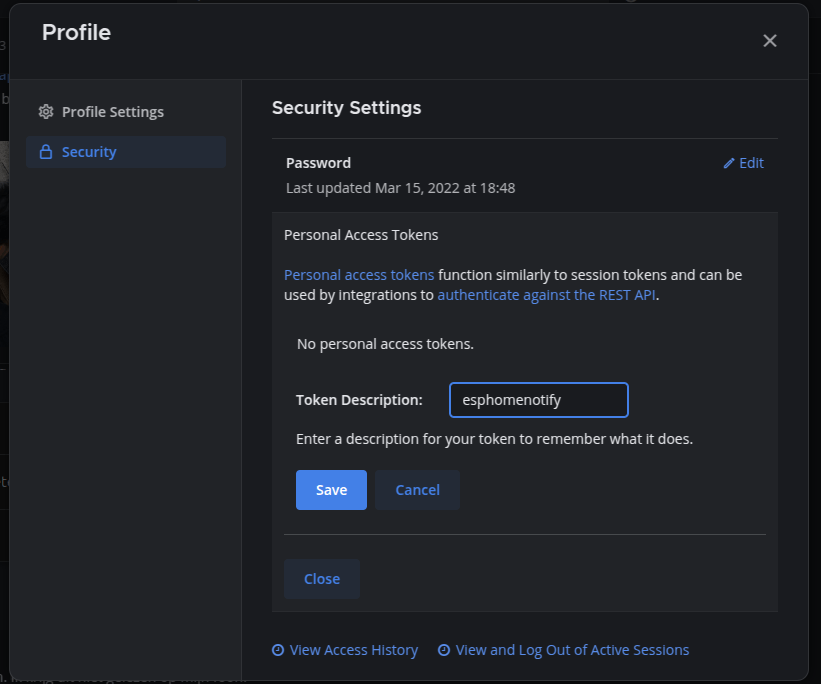
Get a Long-lived access token from HA:
Profile > Security and Create Token
Create a token in Mattermost: