Last Updated or created 2024-08-22
Writing tools and effects for my new boot demo.
- Started a generic sector read/writer
- Some effects
- A sin/cos data writer to include into your source
- Working on a library of functions (sector loaders, color palette, vert/hor retrace functions)
- Laying out a memory map for the demo
Below the output of the sin/cos generator ( see used in video below )
(It also shows a visual plot of the function)
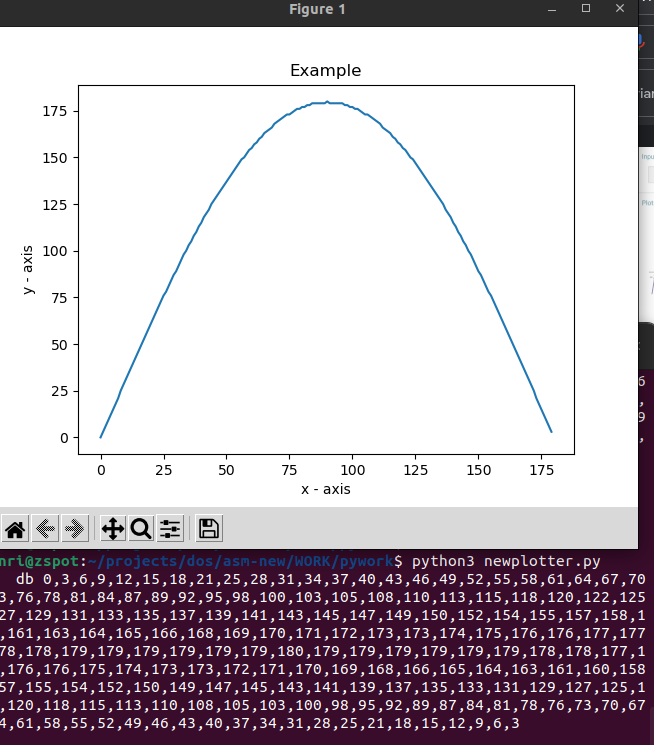
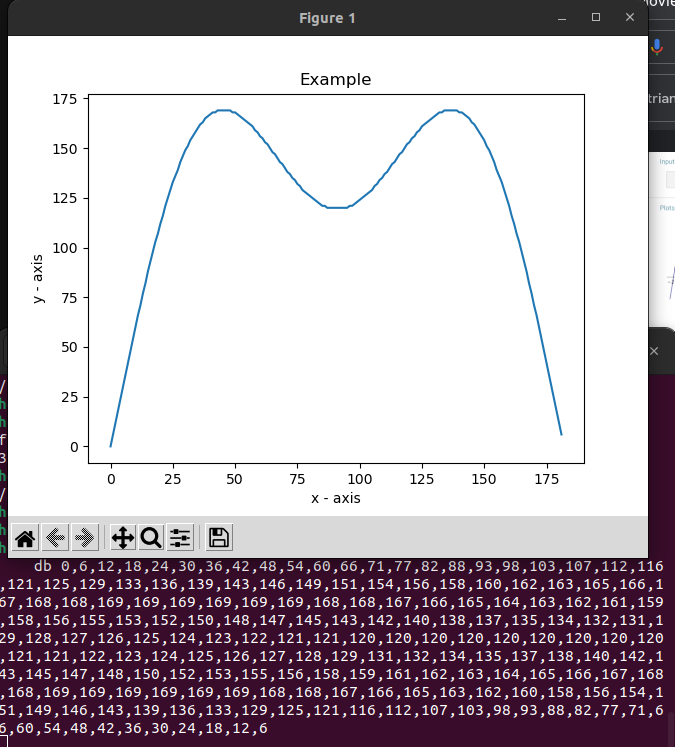
Source code python script
# importing the required module
import matplotlib.pyplot as plt
import numpy as np
import math
# Change these
numberofdatapoints = 360
maxamp = 180
howmuchfromwave = 0.5
numberofharmonies = 1
# Number of harmonies are sin/cos additions in the calculation line below
# not here
step = 360/numberofdatapoints*howmuchfromwave
offset = maxamp
maxamp = maxamp / numberofharmonies
offset = 0
x = [ ]
for xv in range(numberofdatapoints):
xvstep=xv * step
# Calculation line
# datapoint=np.sin(math.radians(xvstep))
# Double harmony example
datapoint=np.sin(math.radians(xvstep)) + (np.sin(math.radians(xvstep*3))/2)
datapoint=datapoint * maxamp
datapoint=datapoint + offset
x.append(int(datapoint))
print(" db ", end="")
print(*x, sep = ",")
# plotting the points
plt.plot(x)
# naming the x axis
plt.xlabel('x - axis')
# naming the y axis
plt.ylabel('y - axis')
# giving a title to my graph
plt.title('Example')
# function to show the plot
plt.show()
Minimalistic very fast boot loader flash screen effect
Graffiti bouncher test (probably ends up bounching a 320×400 image)
This one uses the generated sintab (Using the python script above)
Test code for a text scroller
Code optimalisation/tricks
clear a (double) register?
xor ax,ax
is faster than
mov ax,0h
Want to make ds pointer same as cs?
Instead of
mov ax,cs
mov ds,ax
use
push cs
pop ds
self modifying code
mostly we just move data around, but you also can change the runtime code (instructions)
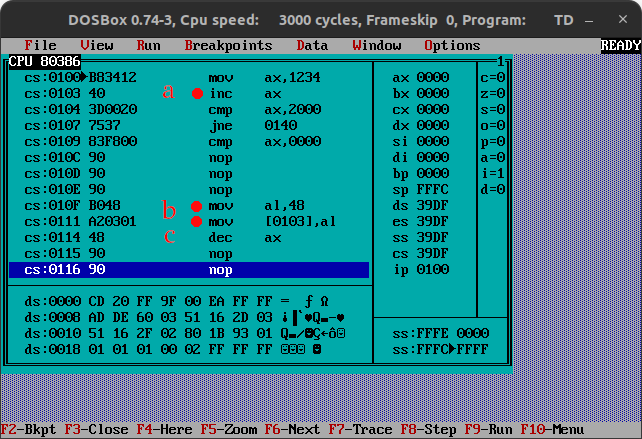
- a – increment ax on line 103h
- b – another part of the code/maybe in a interrupt
10Fh load al with 48h (thats the opcode for decrement (see c)
111h place the opcode in address 103h, which had 40h ..
Now we changed the code to decrement next time
Speedcode/unrolled code
Populair on the C64 where resources are even more limited, you could use speedcode.
Most of the speedcode you generate, due to its repeating lines.
When looking at clock cycles you can save some extra cycles, by using a little more memory but saving on “expensive” loops.
Simple example
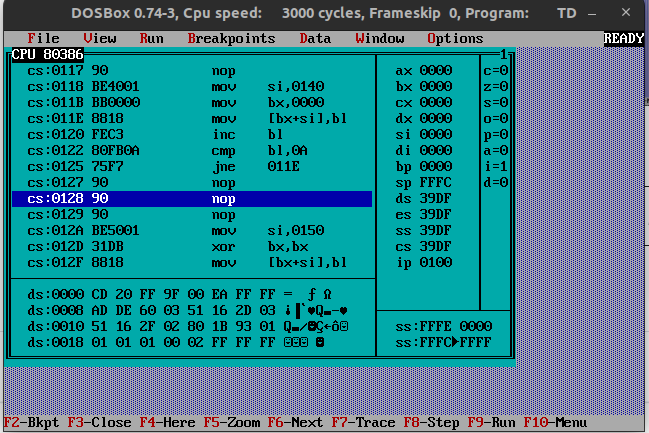
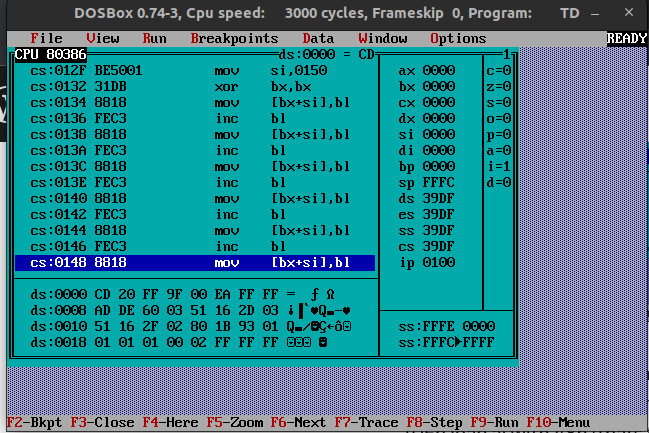
Left a funtion with a loop, right is the same but all instuctions sequencial
Left 15 bytes but 284 cycles
Right 39 bytes but only 102 cycles!
4 4 ; below part 9 times 9 3 4 16 or 4 = 284 cycles Speedcode 4 2 ; xor is faster 9 3 ; even 2 when you can use BX pair! 9 3 9 3 9 3 9 3 9 3 9 3 9 3 9 = 111 cycles (or 102 BX pair)
Moving memory blocks (No DMA)
;DS:(E)SI to address ES:(E)DI
push cs ; example to set es to code segment
pop es
mov si,1000 ; offset pointer source
xor di,di ; destination offset
mov cx,320*100 ; number of transfers (See below words)
mov ax,0a000h ; Destination
mov es,ax ; destination segment
cld ; Clear direction flag set SI and DI to auto-increment
rep movsw ; repeat mov words! until number of transfers is 0
;
Short binary > bcd > dec (ascii) convert for numbers (0-99)
mov ax,01ch ; = 28
mov bx,0ah ; = 10
div bl ; divide BL by AX
; AX = 0802 ; Remainder/Divider
xchg ah,al ; change around (dont use if you want to keep little endian)
add ax,3030h ; offset to ascii 30=0 31=1
; ax ends up with 3238 .. 28